Home // Blog
Home // Notice
Home // Tag Log
Home // Location Log
Home // Media Log
Home // GuestBook
C++ 이야기 스무번째: 상속과 템플릿 특수화를 활용한 Object Size 줄이기 신공! 2/2
Posted at 2008. 8. 2. 11:30 //
in S/W개발/C++ 이야기 //
by
템플릿으로 인한 코드 부풀림 현상
C++ 템플릿 소스는 그 자체로 Object Code 생성되는 소스가 아니라 단순히 사용자 정의 타입(클래스) 또는 함수를 찍어 내기 위한 골격에 불과 합니다. 만약 다음과 같은 코드가 있다면 어떻게 될까요 ?
/// @file template.cpp
class bad_index {};
template <typename T>
class Vector {
public:
Vector(unsigned int sz): arr_(0), sz_(sz), capacity_(sz), next_(0)
{
arr_ = new T[sz_];
}
T& operator [](unsigned int i)
{
return arr_[i];
}
T& at(unsigned int i)
{
if (i > sz_) throw bad_index();
return arr_[i];
}
void add_back(const T& elem)
{
if (next_ == capacity_)
alloc_more();
arr_[next_++] = const_cast<T&>(elem);
}
private:
void alloc_more()
{
T* newarr = new T[capacity_ + 10];
for (unsigned int i = 0; i < capacity_; ++i)
{
newarr[i] = arr_[i];
}
arr_ = newarr;
capacity_ += 10;
}
T* arr_;
unsigned int sz_;
unsigned int capacity_;
unsigned int next_;
};
위 코드는 템플릿 클래스 정의라고 할 수 있는데, 정의 시점에서는 컴파일러가 할 수 있는 일이라고는 문법이 맞는지 또는 자기가 알지 못하는 이름은 없는지 정도만 체크할 수 있을 뿐이고, 실제 Object Code는 생성할 수가 없습니다. 왜냐면 타입 파라미터인 T를 정확히 모르기 때문입니다. new T[sz_] 에서 T를 모른다면 global new 연산자에게 정확히 얼마나 큰 메모리를 할당하라고 호출하지 못할 것이고, arr[i_] 도 일종의 포인터 연산이 이루어져야 하는데, T를 모르니 당연히 연산하는 코드를 생성할 수 없을 것입니다. 그렇기 때문에 위 코드를 컴파일한 후 nm명령으로 symbol table을 확인해 보면 아무것도 나오지 않습니다.
$ g++ -c -o template.o template.cpp
$ nm template.o
$
그러니, 템플릿 클래스에 해당하는 Object Code를 생성하기 위해서는 타입 파라미터인 T 가 정확히 주어지는 시점까지 기다려야 하는 것입니다. 즉, 다음과 같은 코드를 기다려야 한다는 것이죠.
int main()
{
Vector<int*> vpi(10);
vpi[0] = new int(10);
vpi.at(0);
vpi.add_back(new int);
Vector<double*> vpd(10);
vpd[0] = new double(1.1);
vpd.at(0);
vpd.add_back(new double);
...
return 0;
}
이렇게 템플릿 클래스가 실제 사용되는 시점을 템플릿 사용이라고 하고, 템플릿이 사용되는 시점이 되어서야 컴파일러는 Object Code를 생성할 수 있게 됩니다. 이 과정을 템플릿 인스턴스화라고 하고, 이 템플릿 인스턴스화는 타입 파라미터별로 이루어지게 됩니다. 즉, 이 예에서는 타입 하나당 Vector 라는 클래스가 하나씩 생기는 것이죠. Vector<int*>, Vector<double*> 이렇게 말이죠.
그런데 이렇게 두 개의 타입만 생성된다면 별 문제가 없겠지만 다음 코드와 같이 여러 개의 타입에 대해 템플릿 클래스를 사용한다면 어떤 일이 벌어질까요 ?
// 약간 비현실적인 예제이긴 하지만, 나중 설명을 위해 든 예입니다
int main()
{
Vector<int*> vpi(10);
vpi[0] = new int(10);
vpi.at(0);
vpi.add_back(new int);
Vector<double*> vpd(10);
vpd[0] = new double(1.1);
vpd.at(0);
vpd.add_back(new double);
Vector<float*> vpf(10);
vpf[0] = new float(1.2);
vpf.at(0);
vpf.add_back(new float);
Vector<bool*> vpb(10);
vpb[0] = new bool(true);
vpb.at(0);
vpb.add_back(new bool);
Vector<short*> vps(10);
vps[0] = new short(100);
vps.at(0);
vps.add_back(new short);
Vector<char*> vpc(10);
vpc[0] = new char('A');
vpc.at(0);
vpc.add_back(new char);
Vector<long*> vpl(10);
vpl[0] = new long(100);
vpl.at(0);
vpl.add_back(new long);
Vector<long long*> vpll(10);
vpll[0] = new long long();
vpll.at(0);
vpll.add_back(new long long);
Vector<unsigned*> vpu(10);
vpu[0] = new unsigned();
vpu.at(0);
vpu.add_back(new unsigned);
Vector<unsigned short*> vpus(10);
vpus[0] = new unsigned short();
vpus.at(0);
vpus.add_back(new unsigned short);
Vector<unsigned long*> vpul(10);
vpul[0] = new unsigned long();
vpul.at(0);
vpul.add_back(new unsigned long);
Vector<unsigned long long*> vpull(10);
vpull[0] = new unsigned long long();
vpull.at(0);
vpull.add_back(new unsigned long long());
Vector<long double*> vpuld(10);
vpuld[0] = new long double();
vpuld.at(0);
vpuld.add_back(new long double);
return 0;
}
무려 13개의 타입에 대해 Vector 템플릿 클래스가 사용되었습니다. 두 개만 사용되었을 경우, 컴파일 결과 Object Code 크기는
$ g++ -Wall -c -I. -o template.o template.cpp
$ ls -l template.o
-rw-r--r-- 1 yesarang yesarang 6996 Aug 2 07:09 template.o
6996 이고 13개가 모두 사용되었을 경우는,
$ ls -l template.o
-rw-r--r-- 1 yesarang yesarang 27920 Aug 2 07:13 template.o
27920 입니다. 어떻게 소스 코드는 몇 줄 늘지도 않는데, Object Size는 이렇게 많이 늘죠 ? 프로젝트 규모가 작다면 그나마 큰 문제가 되지 않겠지만, 크다면 Vector에 사용되는 사용자 타입이 상당히 많아질 수 있을테니 Object Size가 엄청나게 불어나겠구나라는 생각이 자연스럽게 드실 겁니다. 이런 문제를 가리켜 코드 부풀림(Code Bloat)라고 하죠. C 에서는 일반화된 dynamic 배열을 표현하기 위해 일반화된 방법(주로 void * 활용)을 사용하면 type safety는 보장하지 못하더라도 코드 크기는 별로 늘지 않는데, C++ 에서는 반대로 type safety를 보장하기 위해 코드 부풀림을 피할 수 없게 되는 것이죠. 위에서 제가 정의한 Vector 템플릿 클래스는 상당히 간단한 클래스이지만 실제 표준에 있는 std::vector 는 상당히 복잡한 클래스로 이런 복잡한 클래스에 대해서는 코드 부풀림 현상이 더 심각한 문제가 될 것입니다.
템플릿 특수화와 상속을 결합한 코드량 최적화 신공!
그렇다면 이제 이런 문제를 피할 수 있는 템플릿 특수화와 상속을 결합한 코드량 최적화 신공에 대해서 소개해 드리겠습니다.
앞의 예에서 처럼 여러 종류의 포인터 Vector가 사용되는 경우에 대해서는 이 신공을 멋지게 사용할 수 있습니다. 먼저 다음과 같이 Vector<void*> 클래스에 대해 완전 템플릿 특수화를 합니다.
template <>
class Vector<void*> {
public:
Vector(unsigned int sz): arr_(0), sz_(sz), capacity_(sz), next_(0)
{
arr_ = new void*[sz_];
cout << "constructor for Vector<void*> called\n";
}
void*& operator [](unsigned int i)
{
return arr_[i];
}
void*& at(unsigned int i)
{
if (i > sz_) throw bad_index();
return arr_[i];
}
void add_back(const void* elem)
{
if (next_ == capacity_)
alloc_more();
arr_[next_++] = const_cast<void*&>(elem);
}
private:
void alloc_more()
{
void** newarr = new void*[capacity_ + 10];
for (unsigned int i = 0; i < capacity_; ++i)
{
newarr[i] = arr_[i];
}
arr_ = newarr;
capacity_ += 10;
}
void** arr_;
unsigned int sz_;
unsigned int capacity_;
unsigned int next_;
};
template<> 의 의미는 타입 매개변수 없이 사용할 수 있는 템플릿 특수화라는 의미입니다. 어차피 모든 포인터의 크기는 void*와 다를 바가 없으므로 Vector<T*>의 Object Layout은 Vector<void*>와 다를 바가 없을 것입니다.
그런 연후에 Vector<T*> 이라는 부분 특수화를 다음과 같이 정의합니다.
template <typename T>
class Vector<T*> : private Vector<void*> {
public:
Vector(unsigned int sz) : Vector<void*>(sz)
{
}
T*& operator [](unsigned int i)
{
return (T*&)Vector<void*>::operator [](i);
}
T*& at(unsigned int i)
{
return (T*&)Vector<void*>::at(i);
}
void add_back(const T* elem)
{
Vector<void*>::add_back(elem);
}
};
즉, 상속 관계를 이용하여 Vector<T*>를 Vector<void*>를 빌려 구현하는 것이죠. 이 때, Vector<T*>는 Vector<void*>와 isA 관계라기 보다 isImplementedAs 관계라서 private 상속을 사용합니다. 이렇게 되면 Vector<T*>는 모두 Vector<void*> 구현을 공유하게 되는 것이지요.
얼마큼 효과가 있나 ?
이 신공의 효과는 이론적으로 설명하기 보다 직접 실험 데이터를 보여드리면 확실하게 차이를 느낄 수 있습니다.
다음 그림은 상속과 템플릿 특수화를 활용해서 Object Size 줄이기 신공을 사용했을 때와 사용하지 않았을 때를 비교해 본 그림입니다.
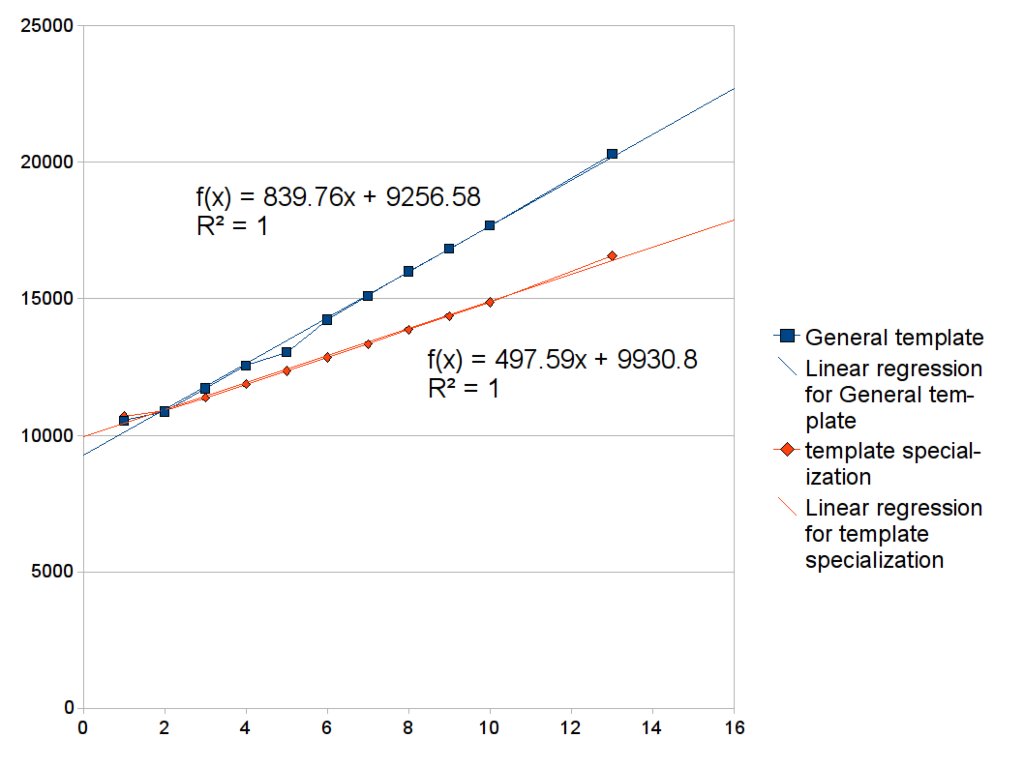
Object Size 비교
일반화된 템플릿을 쓸 때는 한 타입당 840바이트 정도가 늘고, 템플릿 특수화 + 상속의 경우에는 500바이트 정도가 늘어났으니 상당한 차이가 있는 셈이죠.
실험시 사용했던 소스 코드 및 Makefile 을 첨부합니다. 여러분도 직접 한 번 실험해 보시기 바랍니다. 그럼 어느 정도로 차이가 있는 확실히 감을 잡으실 수 있을 것입니다.
 invalid-file
invalid-file제 글이 유익하셨다면 오른쪽 버튼을 눌러 제 블로그를 구독하세요. -> 
블로그를 구독하는 방법을 잘 모르시는 분은 2. RSS 활용을 클릭하세요.
RSS에 대해 잘 모르시는 분은 1. RSS란 무엇인가를 클릭하세요.
블로그를 구독하는 방법을 잘 모르시는 분은 2. RSS 활용을 클릭하세요.
RSS에 대해 잘 모르시는 분은 1. RSS란 무엇인가를 클릭하세요.
 이상계는 이쪽에 속해있지 않고 저쪽에 속해 있다. 이쪽에 사는 우리는 이쪽에 머무르지 않고 저쪽을 꿈꾸며 살아야 한다. 여기 오는 모든이들이 저쪽의 충만함을 이쪽에서의 매일의 삶에 경험할 수 있기를...
E-mail: (yesarang) at (yahoo.co.kr)
이상계는 이쪽에 속해있지 않고 저쪽에 속해 있다. 이쪽에 사는 우리는 이쪽에 머무르지 않고 저쪽을 꿈꾸며 살아야 한다. 여기 오는 모든이들이 저쪽의 충만함을 이쪽에서의 매일의 삶에 경험할 수 있기를...
E-mail: (yesarang) at (yahoo.co.kr)
